AI教程
如何准备训练音频 什么样的音频属于合格的训练素材
- 2025-04-20
- 朴老师
- 本站原创
今天在这里主要是教大家如何准备训练音频,想要训练一个好的音色模型,首先要准备好训练用的音频,这里需要大家提供十分钟说话音频,和十首唱歌干音(干音指的是没有背景音乐只有纯人声唱歌),在经过处理之后就可以使用了!
整合包下载地址:https://ai8.net/fuli/2024/1227/590.html(点击链接即可跳转)
前期准备工作
下载百度云文件
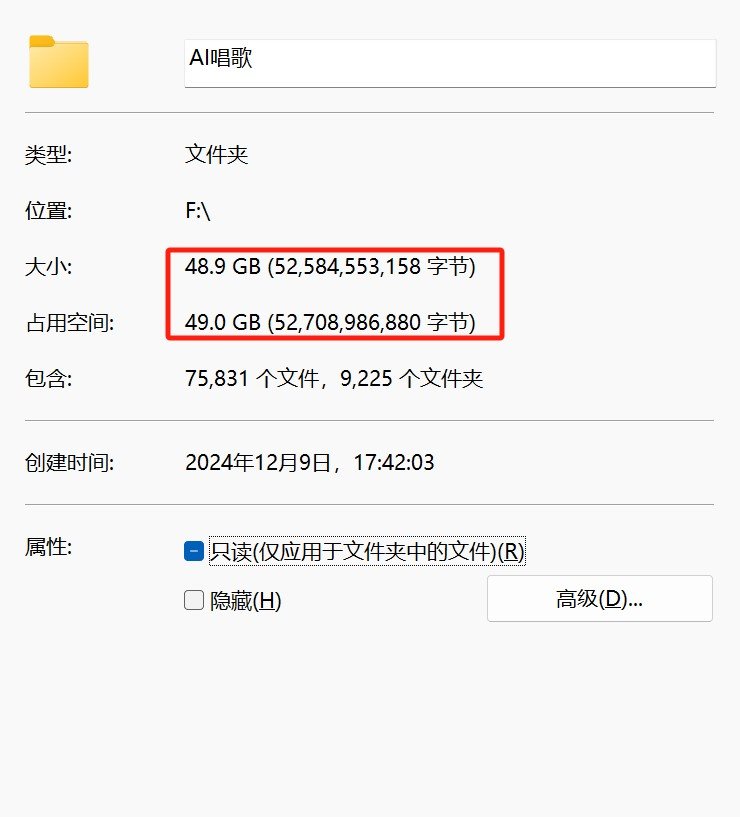
在获取到百度云链接后,首先要将文件都下载下来

这里小编建议文件存放的硬盘空间一定要足够大,因为文件解压后,占了将近50G的空间,如果空间不够大会导致文件无法完整解压,这也会导致软件无法顺利使用!
文件解压
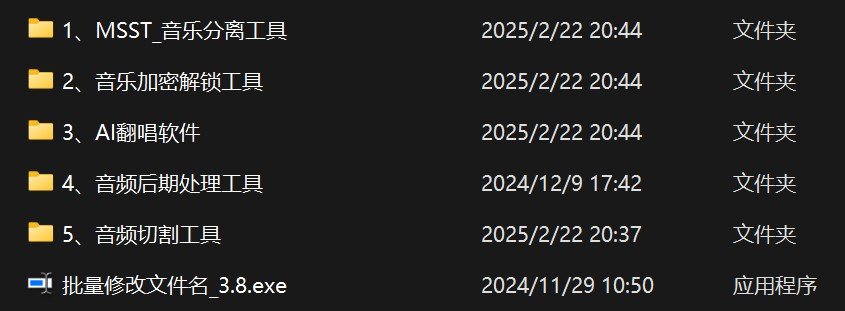
在全部下载好之后我们就会看见这七个项目,最常使用到的是【1.MSST 音乐处理工具】、【2.音乐加密解锁工具】、【3.AI翻唱软件】,大家如果只是想替换音色,并没有自己训练音色模型的想法,那么就只解压这三个文件就行。
如果后面想要自己训练音色模型,那就把【4.音频后期处理工具】、【5.音频切割工具】这两个文件也解压并安装。
如何解压
因为这篇文章主要是讲述如何使用处理训练用的音频,这里我就只展示如何解压【4.音频后期处理工具】这一个文件夹。
首先我们点开【4.音频后期处理工具】文件夹,找到压缩包。

而后鼠标右键点击,找到并点击解压选项即可
如何准备并处理音频
首先我们新建一个目录,将不低于10分钟的说话音频和十首清唱音频存放进,如果想要用于训练则需要将音频都切成15秒以内的小段。
这时我们就需要用到AU软件,首先将AU软件打开,并将要处理的音频输入。
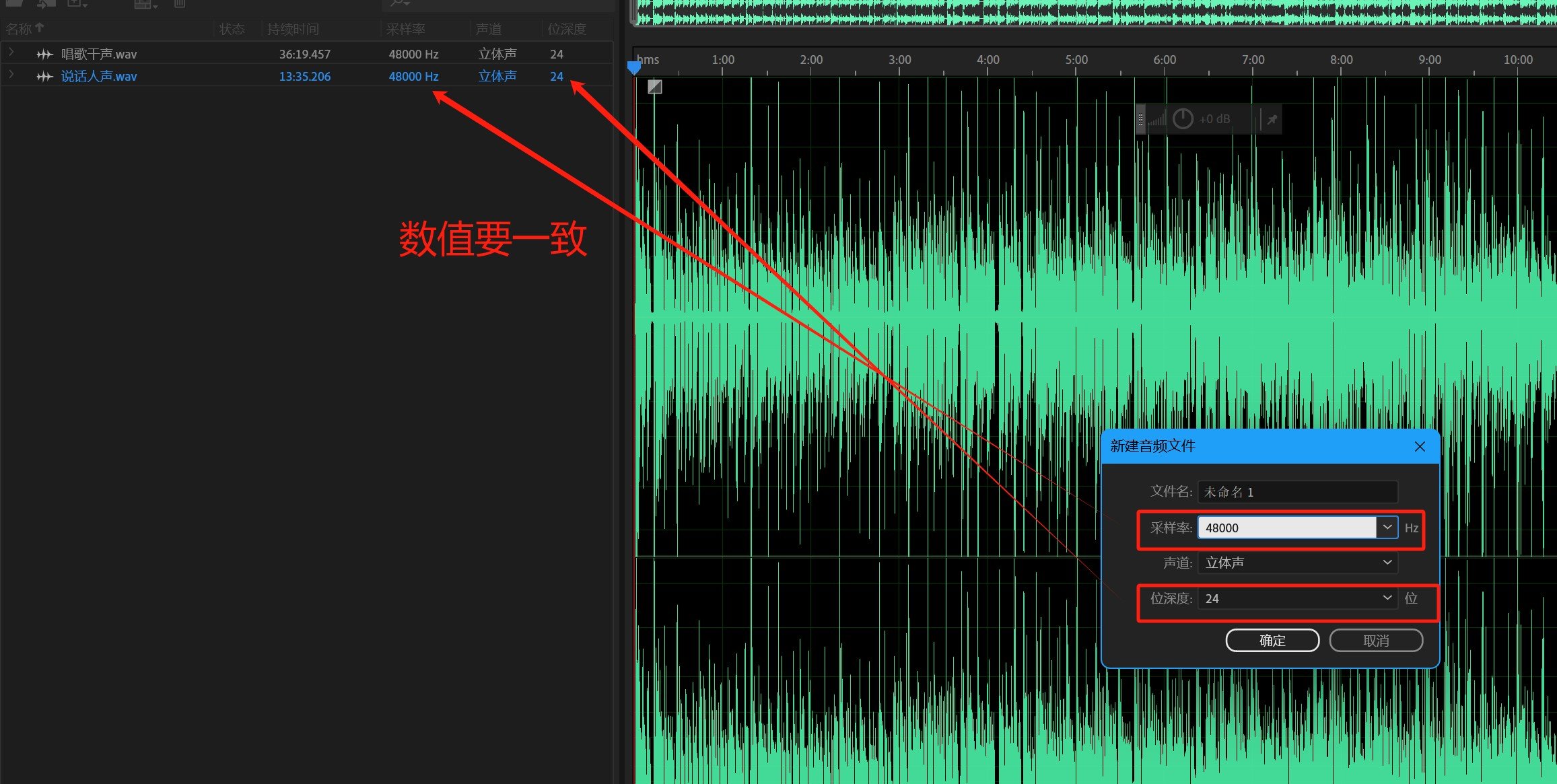
之后键盘按住Ctrl+shift+n,就会蹦出【新建音频文件】界面,将采样率调到与音频采样率是一样,位深度也一样。
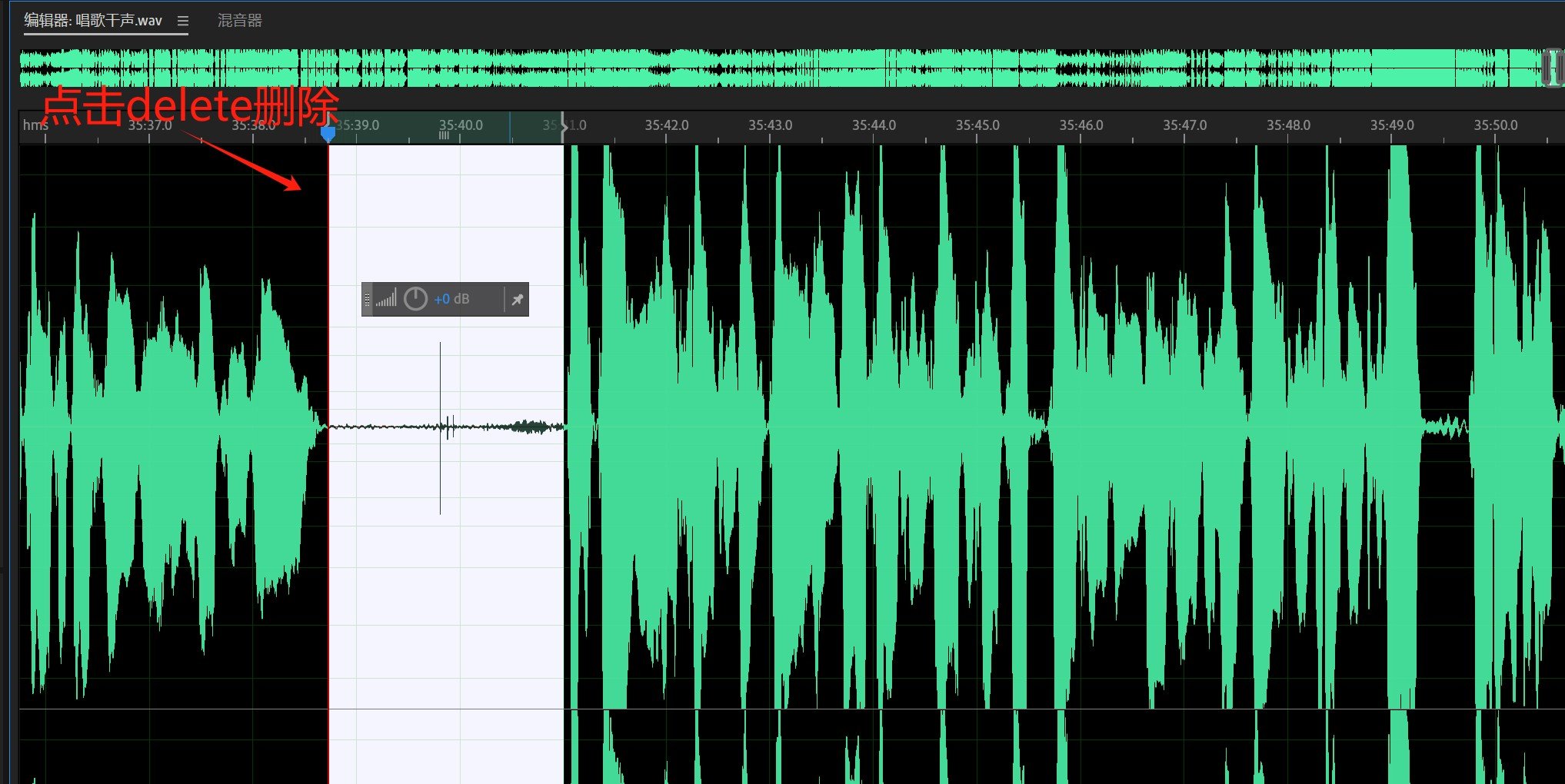
我们需要把这种没有声音的地方去除,至于如何去除呢,那就需要选中要删除的位置,而后按键盘上的【DELETE】这个键,一按它就删除了。
之后找到有声音的地方,并以15秒为一段,然后点击Ctrl加x键把声音剪切,再Ctrl加v粘贴到未命名文件里,记住我们模型训练参考音频质量一定要高,不要是那种很垃圾的,或者说背景杂音很多的,一定要是处理好的,没有什么伴奏,且为纯人声的那种音频。
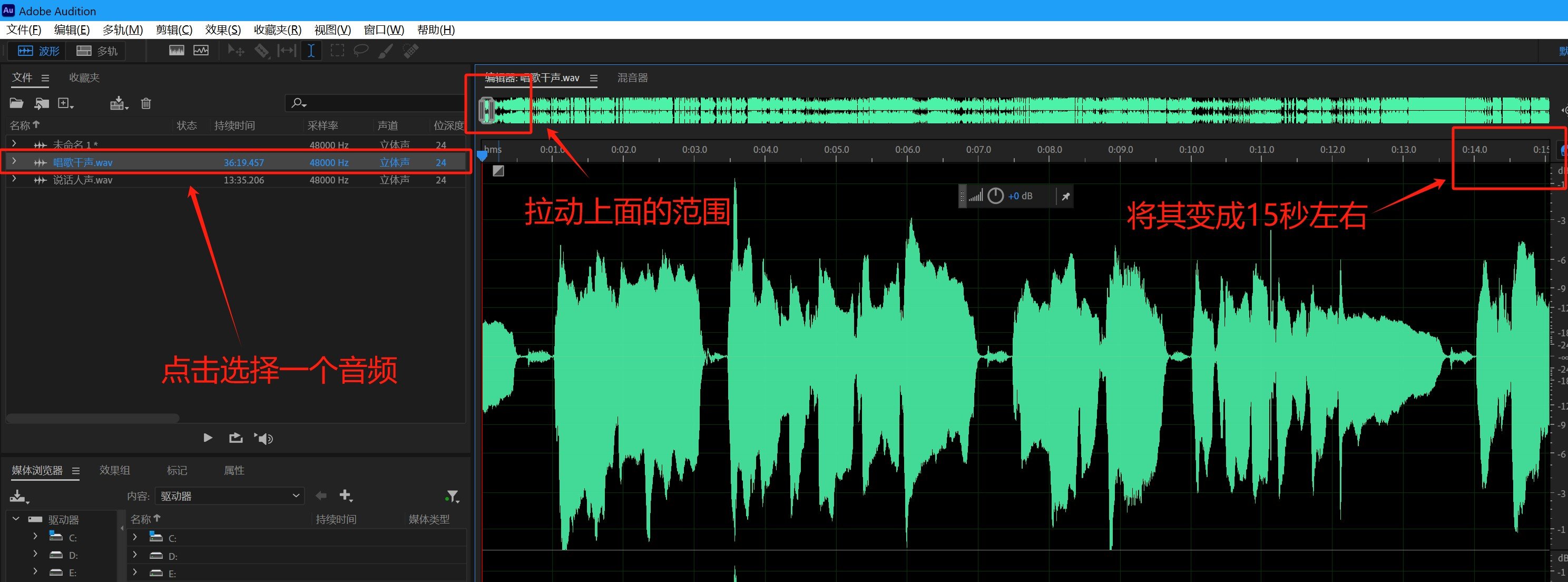
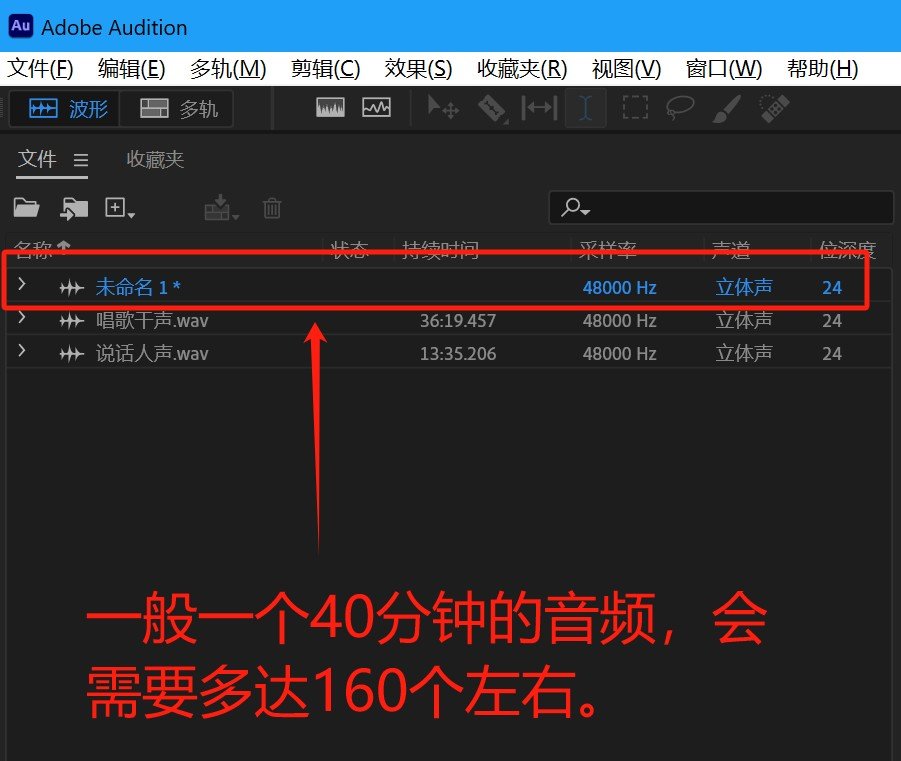
之后就要一点点将音频全部分离出成15秒左右,一般全部音频处理完,可能会有100多个这种未命名的文件夹。我们全部都处理好了以后,点击【文件】,然后选择【全部保存】,保存好了以后就直接确定,这样他就慢慢的,一个一个全部都保存了。
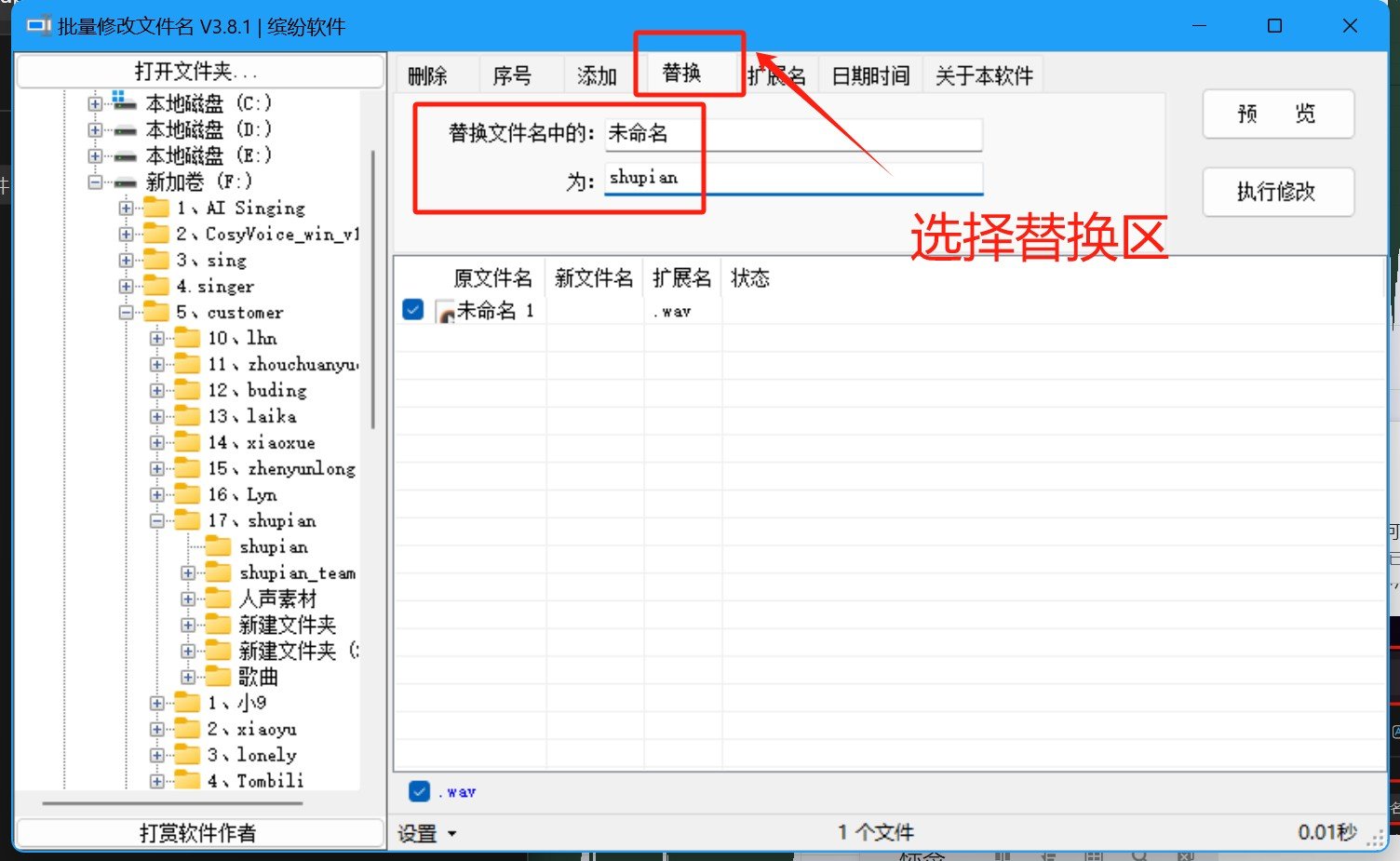
全部处理好以后,他就会到你保存的文件夹里面,文件夹的名字最好是英文,数字的,就是不要带中文,一定一定不要带中文,包括里面的训练音频也不要是中文,像是在AU保存完之后,它的文件的名字为未命名加数字这样的形式,那要怎样以最快的速度将中文换成英文或者数字呢?

我们就要点开,批量修改文件名工具,而后找到,刚才我们保存的文件,选择【替换】区,并将文件中的中文替换成英文或者数字,并点击【预览】,而后选择【执行修改】,那么这些音频最后处理的步骤就做完了。
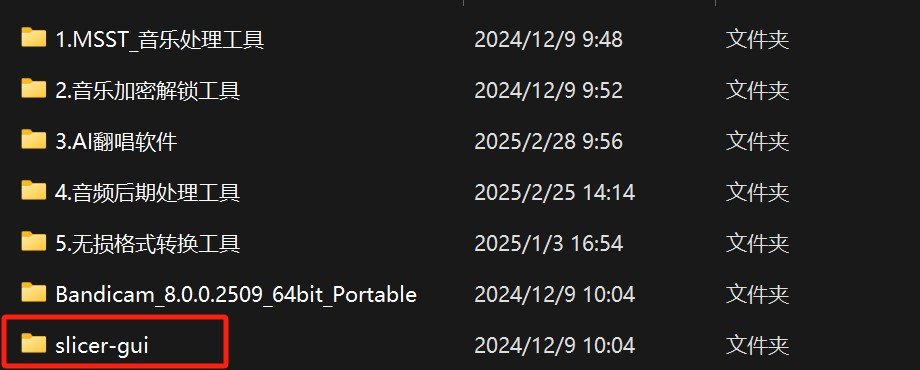
当然了,切音频不一定非要是手切,也可以使用软件代替,我们找到【slicer-gui】文件夹,将其打开。
双击【slicer-gui.exe】就可打开音频切割软件。
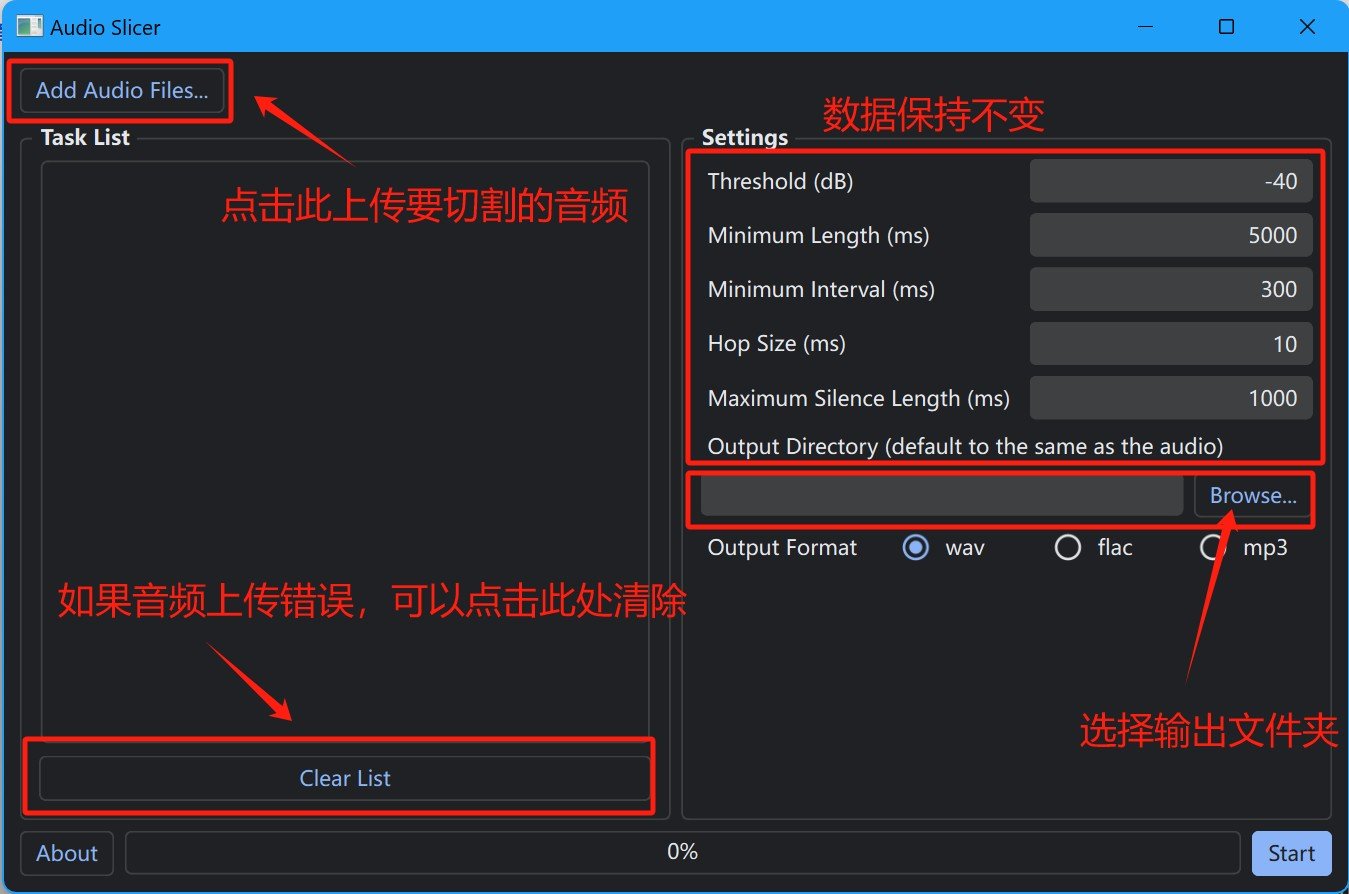
点击上方【Add Audio Files】上传需要切割的音频,要是音频上传错误也可以点击【clear List】清除,而后右边的数据保持不变,并点击【Browse】选择输出文件夹,之后就可以点击【start】开始切割了,不过要注意的是,切割的音频时长要在3-15秒之间,低于3秒的要删除,高于15秒的,要进行二次切割,可以使用切割软件也可以使用上述的AU进行操作!
以上就是什么样的音频属于合格的训练素材全部内容,至于这些音频如何作用则需要查看【训练音色模型方法介绍 如何使用AI翻唱软件训练音色模型】教学文章